Software Architecture Consulting
- Software architecture is the process of using operational and technical requirements to design robust, high quality and secure solutions.
- Software development techniques and architectures that have evolved over the years include client-server, object-oriented, domain-driven, onion, aspect-oriented, service-oriented, microservices, lambda, component-based and event-driven.
- At Cazton, our experts have years of real-world hands-on experience in implementing different software architectures and design patterns. We help Fortune 500, large and mid-size companies build modular, scalable, maintainable and testable software solutions.
The term architecture generally means the practice of designing or building something. Software architecture is the process of using operational and technical requirements, and designing a solution that optimizes things important to the system like quality, performance, security, and maintainability. If we envision what is needed to build software, it is similar to the process of constructing a building. In the latter, architects first start by selecting a site. It is then cleared by creating a solid foundation. Architects and workers then erect the building's core structure, build the floors, level by level; interconnect the entire building with wires and plumbing, and finally finish off the interior and exterior of the building.
Software architecture also goes through a similar process. While building a software, the architects have to first choose an environment, infrastructure and frameworks that fits the requirements. Choosing the correct environment and infrastructure creates a foundation, on top of which the entire software works. After the foundation is set up, developers start building various layers and pieces of the software, which are then interconnected so that data can flow across of the layers. In this entire process, the architecture of the software is the most important part as it builds the core foundations of that software.
Over the years, the software industry has seen a tremendous change in the way, software has been built. New techniques have evolved, which have helped solve problems. Let's take a look at different types of software architectures.
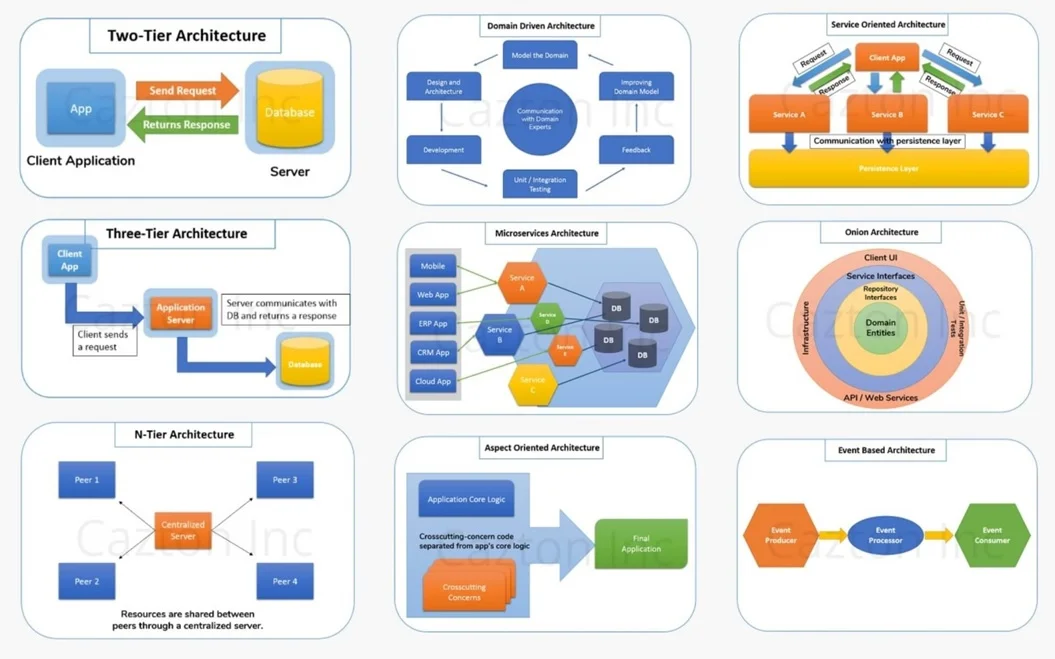
-
Client-Server Architecture:
Client-server architecture is also known as two-tier architecture, where some services that run on the server are accessed by the client. Before we proceed any further, it is important to understand the difference between tiers and layers. A layer represents the logical presentation and organization of your software code. Think of separating your code in layers like UI layer, business layer and data-access layer. A tier on the other end, represents the physical deployment of these layers. In other words, a tier might be a two-tier, three-tier or n-tier architecture, where different pieces of software are deployed at different places. That being said, in client-server architecture, the presentation layer or interface runs on a client machine and a data layer or data service runs on the server, thus creating direct communication between the two. Separating these two components into different locations represents two-tier architecture. Though this architecture may be good for small and monolithic software, but this approach has quite a few disadvantages that have resulted in evolution of three-tier, n-tier and peer-to-peer architectures.
-
Object-Oriented Architecture:
This architecture is one of the most important and commonly utilized for developing software. The entire application is divided into separate responsibilities and the system is known as a collection of objects. This architecture promotes various object-oriented concepts like Encapsulation, Inheritance, Polymorphism, Composition, Association, Objects, Classes and much more. The style of creating object-oriented software's is completely different from functional or procedural style. A software built by strictly following the object-oriented concepts makes it highly robust, scalable, reusable, maintainable and testable. It also reduces development time and cost.
-
Domain-driven Architecture:
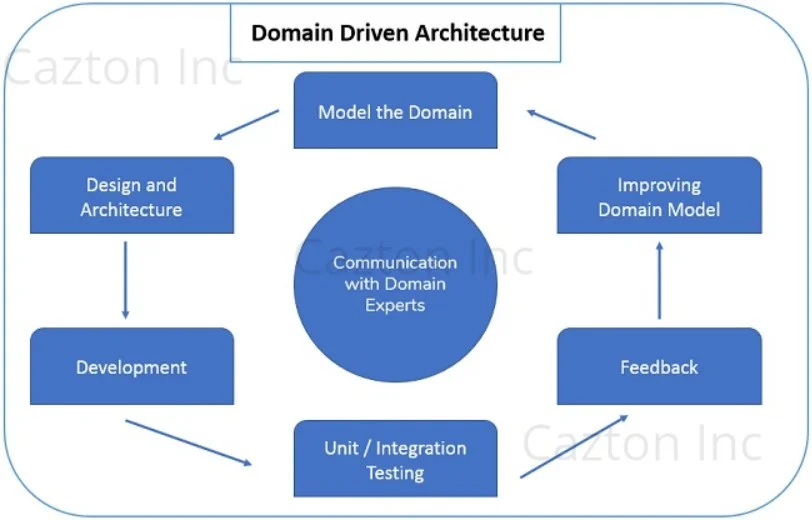
A very general definition of the term domain means a specified sphere of activity of knowledge. In relation to software development, DDD focuses on the subject area for developing the application. Domain Driven Architecture, also known as Domain Driven Design (DDD), is one of the most widely accepted architecture used to build enterprise applications. It is based upon the very famous principles of object-oriented analysis and design. DDD primarily focuses on the plan to solve business problems. It allows us to create better software, focusing on the domain model, rather than the technology. It talks about associating different entities of your software. It introduces concepts like entities, value objects, domain modeling, ubiquitous language, bounded context and anti-corruption layer. It helps developers create a more requirement-oriented software and help them stay focused on the solution. It places clean boundaries around pure models and help better organize elements of your enterprise architecture.
-
Onion Architecture:
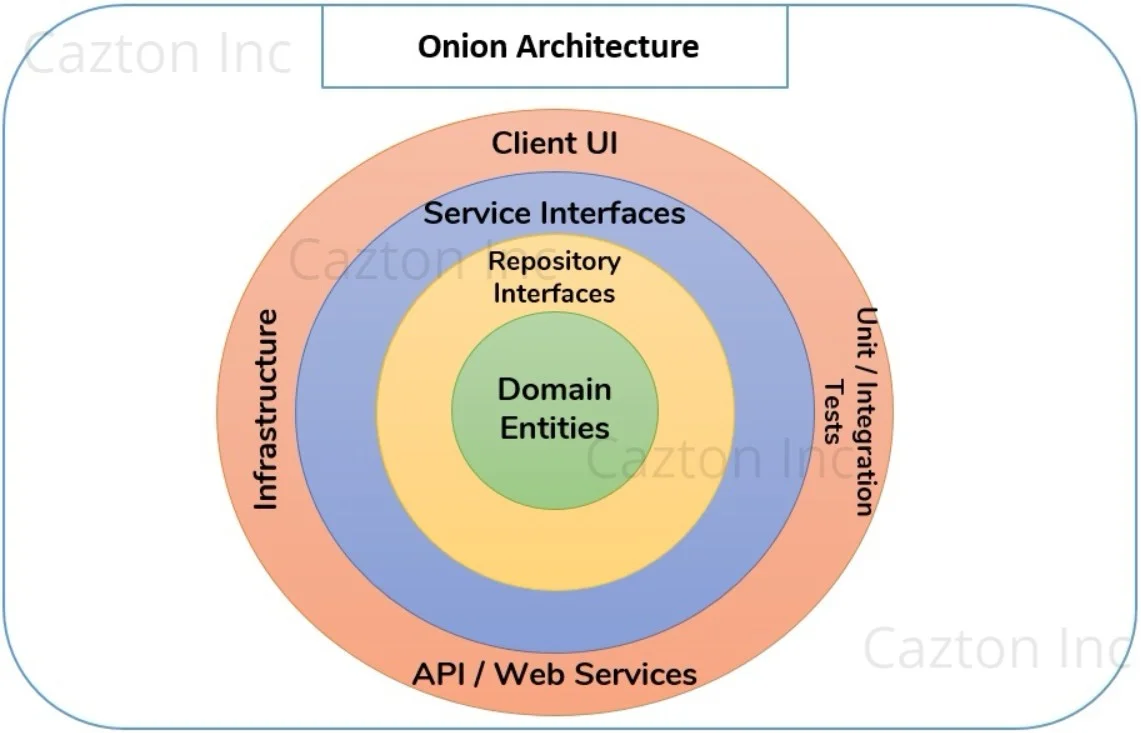
Traditional architecture, which is mostly database-centric, raises fundamental issues related to separation of concern and tight coupling. All the layers (UI, Business Layer, Data Access Layer) are tightly coupled as they depend on each other for flowing data. This raises major issues as the application grows bigger.
Onion architecture on the other hand controls coupling. The fundamental idea of this architecture is that your domain entities remain at the core (the inner-most) layer. The outer layer would be your repository interfaces that would utilize your core domain entities. The repository layer only defines interfaces to be utilized by other outer layers. The implementation code of your repository comes in the outermost layer called the Infrastructure layer. The repository interfaces are utilized by service layer that holds your business logic. The outermost layer that includes your UI, Infrastructure and Tests, utilizes your service layer.
In a nutshell, the idea is that the inner layers of the application cannot and should not depend on the outer layer, but the outer layer can depend on the layers beneath it. This way it does not matter which database technology you depend on or which ORM is introduced because the innermost layers do not depend on them. Thus, onion architecture enables us to write more maintainable and testable code that emphasizes on separation of concerns throughout the system.
-
Aspect-Oriented Architecture:
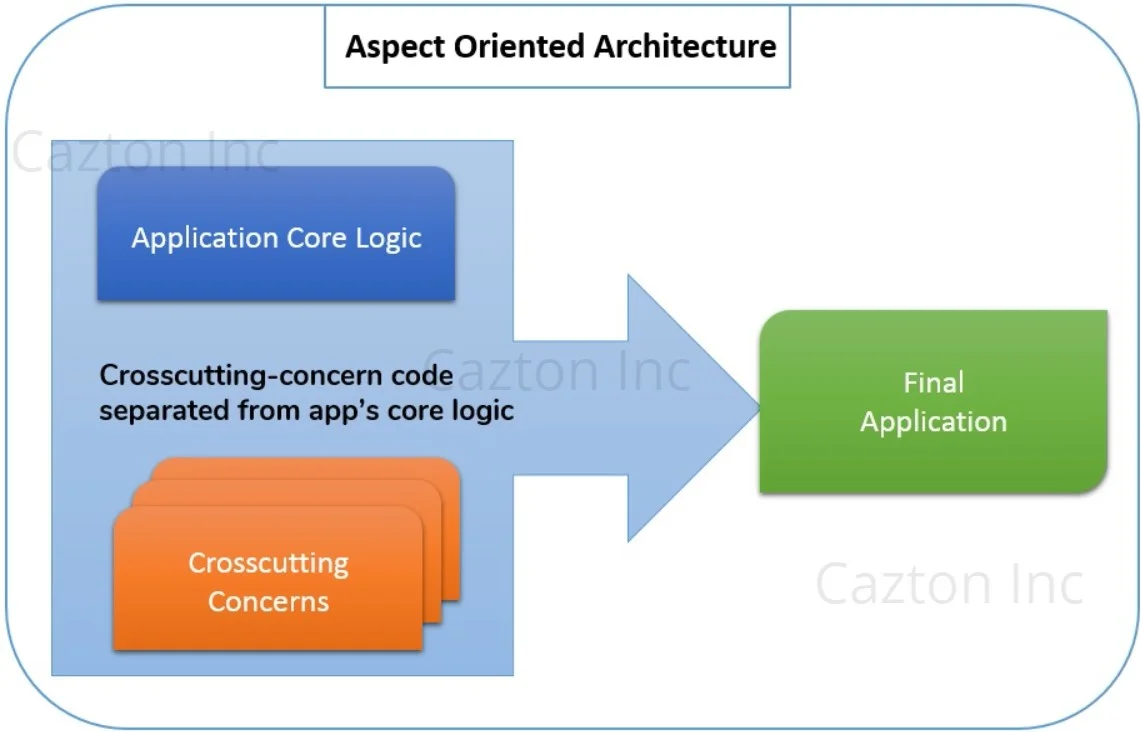
Aspect-Oriented Architecture has gained a lot of traction lately due to its focus on fixing the modularity issues, which other architectures sometimes fail to offer. It enhances your existing design architecture, rather that completely replacing it. Developers usually focus on creating a modular software that helps them keep their code maintainable as well as reusable. Aspect Oriented Software Design (AOSD) focuses on just that. In any enterprise level software, there are various cross-cutting such as logging, persistence, security, data transfer. AOSD helps you separate them from your business logic. It helps you break down the software logic into distinct parts, thus making the code more modular and smaller in size. It helps reduce software design, development and maintenance costs.
-
Service-Oriented Architecture:
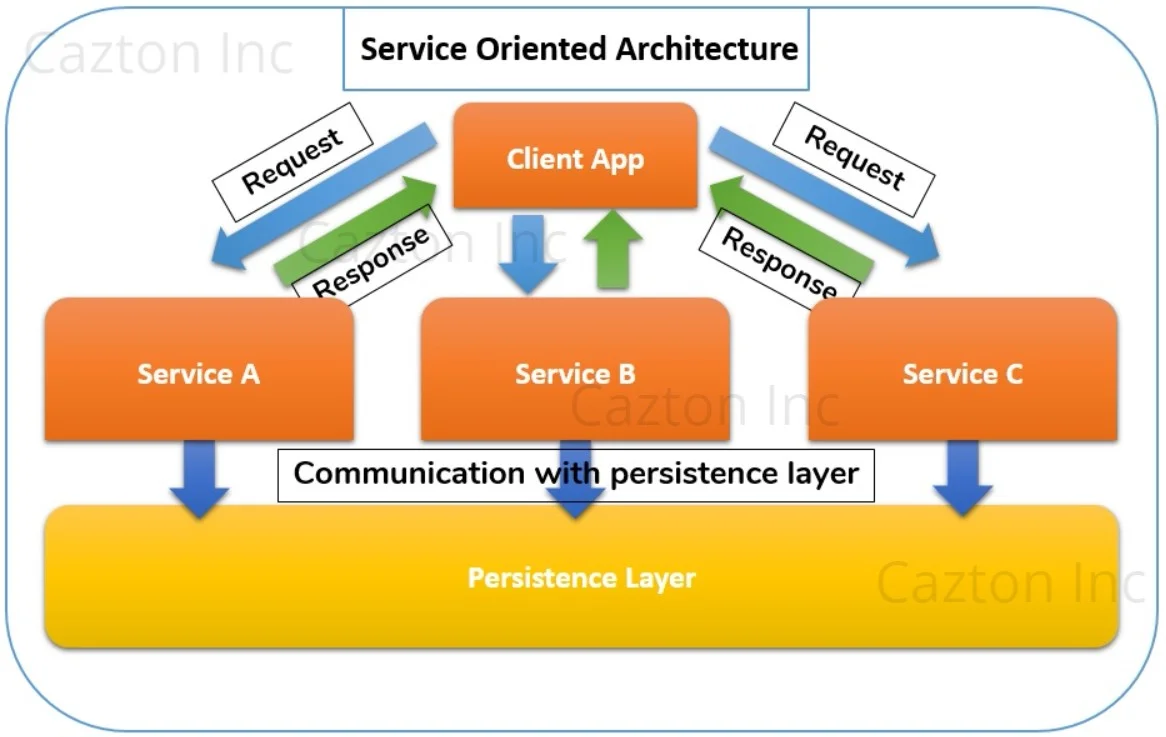
Service-oriented architecture is basically a collection of services that communicate with each other. These services are modular in nature and provide a plug-n-play environment that serves a particular purpose. They are reusable, so that developers do not have to write the same services again. They are loosely coupled and exposed via interfaces that can be consumed by other software components. Any request sent to these services has a response that follows a common protocol, which is accepted by a wide-range of consumers. You can think of SOA being implemented as Web Services or APIs, which can be deployed and accessed remotely. SOA is known to provide both time-to-market advantages, as well as business agility.
-
Microservices Architecture:
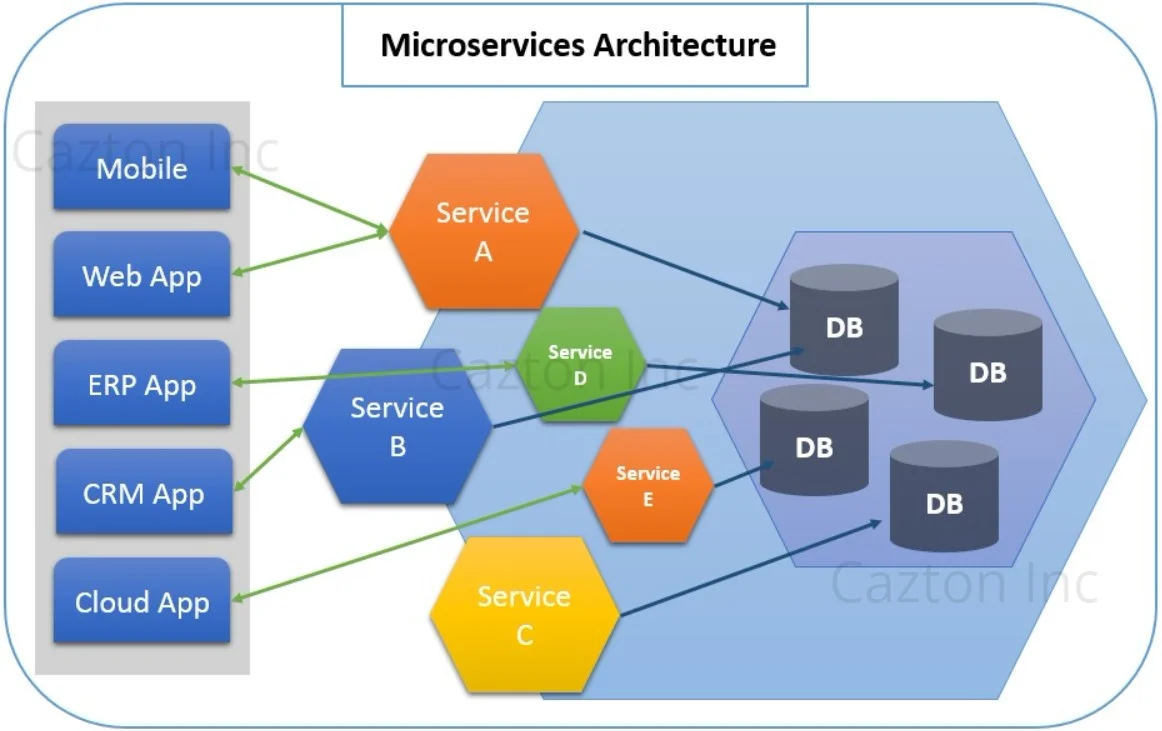
Over the years, we have been building software where different layers of the application were built together. Different teams work on different layers and build together a product that is very easy to develop, test and deploy. This practice can be represented as a monolithic architecture. The drawback of this architecture is that as the application grows, the codebase starts intimidating developers and if new members join the team, it becomes difficult for them to understand the structure quickly. Large applications that are tightly coupled are often very difficult to deploy and scale and switching the entire codebase to a new technology also becomes a big challenge. This is where a new architecture comes into the picture as it addresses these limitations. It is called as The Microservices Architecture.
A microservice architecture is the evolution of service-oriented architecture, but is still different in terms of implementation. A microservices architecture consists of a collection of small, self-contained, autonomous services that encapsulate a single business capability. These services are very small, independent and separate code-bases, which are self-deployable. Each service may have its own database in order to be decoupled from other services. All these features allow developers to focus on a single service rather than looking at the entire application. Development, testing, deployment, scaling and switching to new technologies also become very easy. Microservices have seen widespread adoption and it seems very promising.
-
Lambda Architecture:
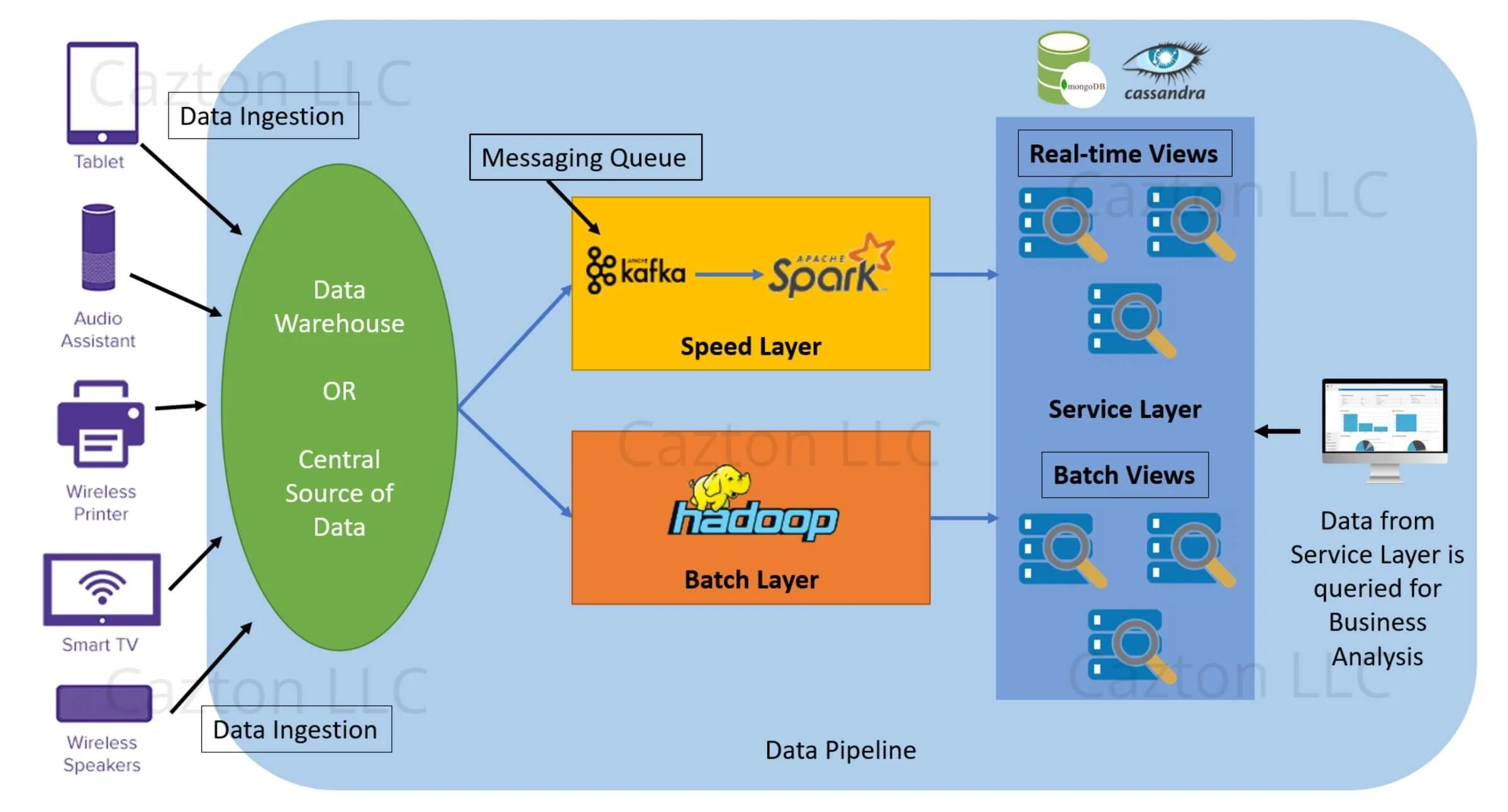
In the Big Data world, there are scenarios where you want to ingest data from different data sources. Some sources may provide data in batches whereas some provide real-time data as streams. In such scenarios Lambda architecture stands out and helps ingesting both batch and stream data. The term Lambda in the word Lambda Architecture comes from the mathematical lambda symbol. This architecture became very famous in the Big Data industry and has been used with Big Data technologies like Spark & Hadoop. However this architecture is not specific to Spark or Hadoop. It is a generic architecture that can be applied with any set of technologies. Read here to learn more about this architecture.
-
Component-based Architecture:
A software application can be divided into multiple components, where each component is a modular, reusable and portable piece of unit that encapsulates a particular business functionality. The primary objective of component-based architecture is to ensure component reusability. The primary characteristics of CBA are reusability, extensibility, independent and encapsulated. Interfaces are exposed, so that each component can communicate with the other. It provides more control and a wide range of customization options to developers.
-
Event-driven Architecture:
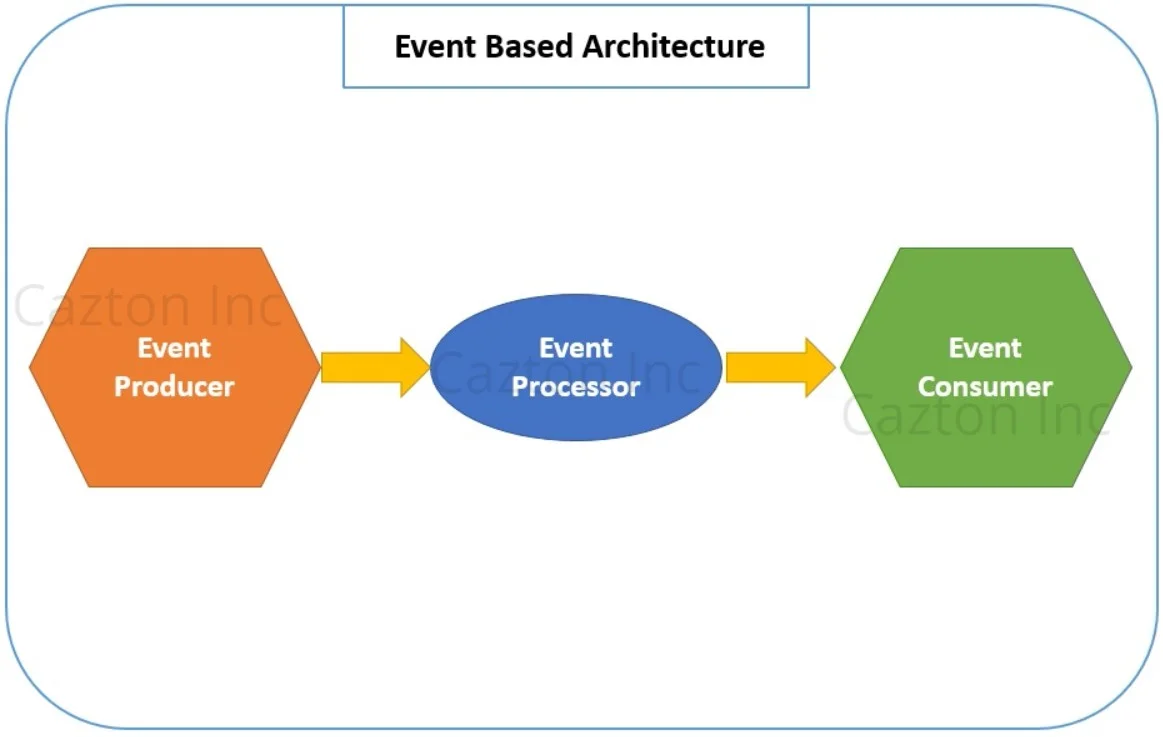
As the name implies, an event-driven architecture usually deals with the events produced and consumed between different software components. This architecture usually contains at least three decoupled players (the producer, pipeline and the consumer). The producer is the one who emits an event. It is completely unaware about what happens to the event after it is emitted. It does not care how the event is going to be processed or consumed by any other software component. The pipeline is where all the events from various producers are queued up for processing. After an event is processed, it is forwarded to its consumers. Event-driven architecture promotes a publisher-subscriber model. It is also referred to as message-driven architecture or stream-processing architecture. This architecture enables both producers and consumers to be completely decoupled, and allows plugging in more producers and consumers. It can be used to create highly scalable and distributed applications.
Please note that, the applicability or implementation of all the above-mentioned software architectures depend on various factors. One has to accept the fact that an architecture used in developing Software A may not be applicable in developing Software B. We at Cazton, have experts who have decades of real-world hands-on experience of implementing these software architectures and design patterns in a wide variety of software projects that are modular, maintainable, testable and futuristic.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.