Cassandra Consulting
- Apache Cassandra is an open-source distributed, scalable, fault-tolerant NoSQL database that allows us to store petabytes of data with best-in-class performance.
- It offers elastic scalability, highly availability, tunable consistency along with cassandra query language (CQL) and a strong community.
- At Cazton, we help Fortune 500, large and mid-size companies with database best practices, development, performance tuning, consulting, recruiting services and hands-on training services.
- Our database and scalability experts have a proven track record of successful software projects while saving millions of dollars to customers.
Did you know there are more than 1500 companies using Cassandra to handle huge volumes of data? Did you know that some of the largest production deployments include Apple's, with over 75,000 nodes storing over 10 PB of data, Netflix (2,500 nodes, 420 TB, over 1 trillion requests per day), Chinese search engine Easou (270 nodes, 300 TB, over 800 million requests per day), and eBay (over 100 nodes, 250 TB)? (Source: Cassandra's official website)
Huge organizations collect mission-critical data every single minute from various sources. This data can expand up to terabytes and petabytes and it is important to have a highly available, scalable and robust data storage for maintaining this ever-growing data. When it comes to scalability, NoSQL databases top the list. There are many NoSQL databases available in the industry today and all of them have their own advantages and disadvantages. NoSQL databases, since their emergence, have been a strong contender for data storage and processing requirements of modern applications. NoSQL databases are inherently more scalable than SQL databases as they allow you to scale vertically and horizontally. Whereas most SQL databases are vertically scalable by design. These databases can be deployed as distributed systems, which makes them more reliable and faster while querying for data.
One such powerful database is Apache Cassandra. Cassandra is an open-source distributed, scalable, fault-tolerant NoSQL database that allows us to store petabytes of data with best-in-class performance. It was created by developers at Facebook in the year 2008 with the goal to solve their inbox search problem and use it as a storage infrastructure for many problems of the same nature. It can be used to store dynamically structured data that can be scaled to thousands of commodity servers spread across multiple datacenters in the world. Though Facebook created Cassandra to solve their data related problems, they later open-sourced this software under Apache's license. In its early days, Cassandra received a lot of interest by many organizations and it was also ranked as one of the top 10 NoSQL databases.
Cazton experts have more than a decade of experience in creating highly scalable systems with high performance that are cost-effective. We have real world experience using this technology and leverage its overall capabilities in many different scenarios. We can help you make the right decision to achieve your business goals. We have the expertise to understand your requirements and tackle your data problems. Continue reading to learn more about Cassandra's architecture, its top features and our services.
Apache Cassandra Architecture, Partitioning, Replication & Storage Engine
When the developers at Facebook started planning to fix their inbox search issues, they took inspiration from both Amazon's DynamoDB and Google's BigTable. With Cassandra, these developers brought in the distributed feature of DynamoDB and the dynamic data model feature of BigTable. Later when Cassandra was open-sourced under Apache, that's when a lot of real changes and improvements were brought in. Lots of efforts have been put in by the Cassandra community. And over a period of 12 years, Cassandra's new version v4.0 is inline to be released soon. More details have been given below.
Now that we have a fair bit of idea of what Cassandra is and how it started, let's take a look at its architecture.
Cassandra was built for a distributed environment. If you are dealing with Big Data, there's a high possibility that Cassandra can fit into your use case. Cassandra has been built to work with more than one server. You can use Cassandra with multi-node clusters spanned across multiple data centers. From a higher level, Cassandra's single and multi data center clusters look like the one as shown in the picture below:
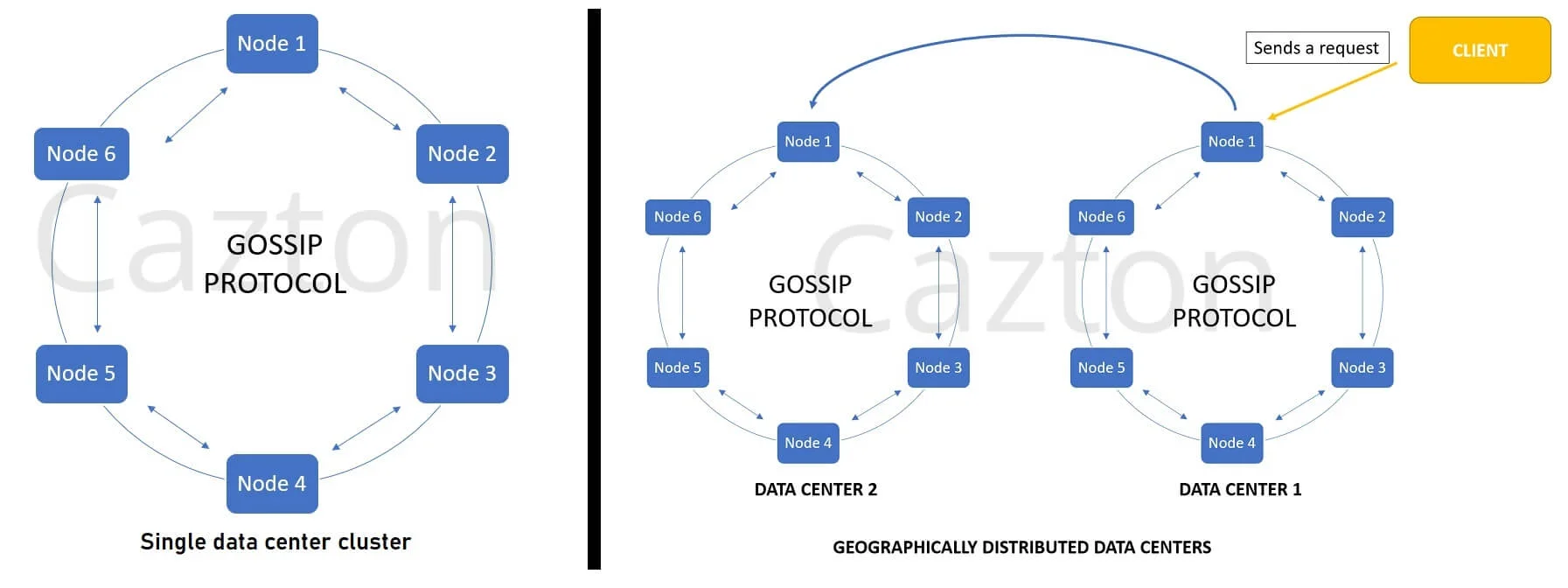
Cassandra architecture across data centers
The above pictures show Cassandra clusters, which are basically a series of commodity servers (having their independent space and memory) connected with each other in a peer-to-peer architecture and communicating using the Gossip protocol. Cassandra offers linear scalability, which means more servers/nodes can be added in a cluster if needed. The more the number of nodes, the better throughput it offers. For higher availability, it is recommended to have at least three servers in a cluster, which can span up to thousands.
Partitioning:
To distribute data across multiple nodes in a cluster, Cassandra uses the concept of tokens. Cassandra has Partitioners which is basically a hashing function to generate tokens from a primary key. Each row of data stored in Cassandra is uniquely identified by a primary key. This partitioner generates tokens for all the data. Now depending on the number of nodes in a cluster, these tokens are divided into an equal range of tokens. So for example if there are 4 nodes, a range of tokens equally distributable will be generated and assigned to each node. Now when a SELECT query is fired, Cassandra evaluates a token based on that row's primary key. Since the nodes are already assigned a range of tokens, Cassandra knows which node to contact inorder to fetch data for that SELECT query.
Partitioners play a major role in spreading data across multiple nodes. The partitioner configuration is a global configuration for the entire cluster. There are three different partitioners: Murmur3Partitioner, RandomPartitioner and ByteOrderedPartitioner. Cassandra uses Murmur3Partitioner as the default partitioner if it is not configured explicitly. An important point to note is that once a partitioner is set for a cluster, it cannot be changed without pushing all the data into another cluster. So one should choose the partitioning algorithm very carefully.
Replication:
Now that we have learned how data is partitioned and spread across nodes, let us learn how Cassandra offers fault-tolerance and reliability. Assume a situation where a user requests some data and the node that has to return that data goes off due to an uncertain scenario. In such cases, Cassandra requests data from its replica nodes and returns the result back to its client. This way there's never one single point of failure.
The total number of replicas across the cluster depends on the replication factor. A replication factor defines how many nodes, data will be replicated to. For example: If the replication factor is set to 3, then other than storing data in the primary node, Cassandra will replicate data to two other nodes. Along with replication factors, Cassandra also offers replication strategies. It offers two strategies: SimpleStrategy and NetworkTopologyStrategy. A replication strategy determines how data should be spread across data centers. The SimpleStrategy is used when data is to be replicated in a single data center whereas NetworkTopologyStrategy is used for replication across multiple data centers. Choosing the correct replication factor and strategy can be tricky and it should be set in such a way that you don't incur cross data center latency and face data loss and performance issues due to any failure scenarios.
Storage Engine:
In case of a WRITE request, only one node receives the initial request and later it is replicated to other nodes. Basically when the client sends some data to a Cassandra node (for ex: an update or insert command is fired), it saves that data in a commit log. Any mutation made to the data is first stored in that node's commit log. A commit log is an append only log that stores all mutations locally on the node's disc. This ensures durability as the data still remains persistent in that node even in case of unexpected shutdown.
Once the data is added to the commit log, it is then pushed to Memtable. A Memtable is an in-memory data structure which is based on the database table. So for example if there's a database table called Products, there will be a Memtable corresponding to each row in that table. Each Memtable can store up to two billion columns and is identified by the row's primary key. As soon as the data is stored in both the commit log and the Memtable, an acknowledgment can be sent back to the client signifying the round trip was completed.
Once the client is acknowledged and as the Memtable starts to fill up, it is flushed(written) onto another data file called SSTables. These SSTables are then flushed onto the disc for persistence. As the official documentation says, SSTables are immutable data files that Cassandra uses for persisting data on disk. As the amount of IO operations increases, multiple SSTable files are created on the disc. There's also a great chance that these files may hold some old and new versions of the same data. For ex: If an update command was fired multiple times, with the first one saving incorrect data and the second one overwriting the first, there are chances that these writes are added to different files. Here Cassandra brings in the concept of Compaction, where it first reads the data from all SSTable files and adds them into a new Memtable. Applies a merge sort and based on the latest timestamp it picks the last updated information. In this compaction process, once the merge operation in the Memtable is completed, it writes all the latest data into a new SSTable file and deletes all the old one's.
The above information was for the WRITE process in a single node. So to replicate that data onto multiple nodes across a single or multiple data centers, it uses the partitioning and replication factors that we learned above. Now that we learned how Cassandra internally works, let's take a quick look at some of the top features it has to offer.
Features of Apache Cassandra
-
Highly Availability: As we learned above that Cassandra does not offer a master-slave architecture. It supports a peer-to-peer architecture where each node is connected with each other in a ring form. These nodes do gossiping to keep data consistent across all connected nodes. Due to this nature, if any of the nodes fails, another node comes in to respond to the user's request. There is no single point of failure in Cassandra, thus offering high availability as compared to other NoSQL databases.
-
Elastic Scalability: Cassandra is a database for distributed systems and it offers elastic scalability by allowing its users to scale up and down its clusters without the need to restart that cluster. Users can easily add new nodes or remove existing ones without facing any downtime. And as we increase the number of nodes in a cluster, we can leverage high read and write throughput. This is one of the best features of Cassandra.
-
Tunable Consistency: Data consistency is extremely important in distributed computing. And with a database like Cassandra, which can be scaled up to multiple data centers, having a strong data consistency is super important. Cassandra offers multiple consistency levels: ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM, LOCAL_ONE and ANY. Each consistency level defines a strategy where the number of nodes will respond back to a particular request.
In Cassandra, when a request is received by a specific node, that node is called as a Coordinator and its responsibility is to manage the entire request path and respond back to the client. So if the consistency level is set to THREE, then at least two replica nodes must respond to the request. Similarly if the level is set to ALL, then all replica nodes must respond. So based on the consistency level configured, the coordinator receives responses for requests from other nodes and based on those responses a request can be marked as successful.
-
Cassandra Query Language (CQL): This is the primary language that developers use to communicate with Cassandra. There is a command line shell called CQLSH available to query Cassandra. That tool can be used to create keyspaces, tables and indexes, insert data and perform many more operations.
-
Strong Community: Cassandra is an open-source NoSQL database technology and has a backing of a vibrant community. This community has been working hard to make Cassandra better day-by-day. There are several mailing lists and Slack channels for Cassandra users and developers where people can connect and solve their queries or learn more about the upcoming features in Cassandra.
-
Cassandra Tools & Plugins: There are many tools available with Cassandra one of which is CQLSH which is a command line shell for interacting with Cassandra through CQL. This tool is shipped with the Cassandra package. There are other tools available that can be used to perform load testing on a Cassandra cluster and plugins that enable full-text search capabilities with Cassandra. Cassandra is highly versatile and provides client drivers for more than 15 programming languages.
Cazton Success Story
Cazton team has helped many Fortune 500 clients, mid-size companies and startups create a fool-proof polyglot persistence strategy. A document database, like Cassandra, is an integral component of polyglot persistence. It's usually deceptively simple. Cazton experts have learned a lot from their experiences to create a NoSQL strategy that is extremely cost-effective, futurist, scales out seamlessly and also prevents a degraded user experience in terms of an absolute collapse of the underlying Cassandra architecture. Cazton team has been fortunate to create successful polyglot persistence strategies for applications and organizations that have different scalability needs as well as budgetary constraints.
One of the major problems in the tech industry is to use the same tool or technology for pretty much every other use case. This is common in the data world. Cassandra has its strengths but should not be used as a complete replacement for an RDBMS, a caching engine or a search engine for that matter.
The Cazton team is highly adept to work in all major business domains including financial, tech, airlines, manufacturing, health care, insurance, fintech etc. We provide different case studies and comparative reports before we suggest technologies that will be the best for a particular client or project. There is no, 'one shoe fits all' strategy in the data world. Our team is also very flexible, especially on brown field projects where the tech stack is already determined and there is not much room to make major changes. We specialize in making your legacy stack modern with the least amount of effort.
Contact us today to learn more about what our experts can do for you.
Cassandra 4.0
The Cassandra community is working hard to make this technology better day-by-day. And at the time of writing this article, Cassandra v4.0 is on the verge of its release. The contributors started working on v4.0 somewhere in September 2016 and since then there has been a lot of improvements made. To summarize, we have listed the top features that we can expect with Cassandra 4.0.
- Incremental Repair Model
- Security Enhancements
- Messaging Rewriter
- Audit Logging (New Feature)
- Pluggable Storage Engine
- Kubernetes Support
- Sidecars
- Java 11 Support
- Virtual Tables
- Default Replication Count for NetworkTopologyStrategy
and a lot more... We can expect lots of bug fixes and improvements in this new version. If you wish to learn more about these new features, feel free to contact us.
How Cazton Can Help You With Cassandra
At Cazton, our team of expert Developers, Consultants, Architects, Data Analysts, Data Scientists, DBAs, awarded Microsoft Most Valuable Professionals and Google Developer Experts understand the changing requirements and demands of the industry. Our experts are well versed with all the database technologies be it on-prem or cloud and we have the expertise to help you setup your database infrastructure, tune and improve database performance, and help you make the right decision to achieve your business goals.
We offer the following services for Cassandra at cost-effective rates:
- Polyglot persistence strategy tailored to the customer needs.
- Integrate Cassandra with other Big Data technologies.
- Scale Cassandra clusters to multiple data centers.
- Help you with monitoring and managing Cassandra clusters.
- Help you with setting up Cassandra Data Models.
- Help you work with Cassandra third party libraries and plugins.
- Help you with application development having Cassandra as the database.
- Deploy Cassandra on-prem or on your preferred cloud service.
- Fix any database related issues.
- Automate deployments.
- Perform upgrading and data migration with zero downtime.
- Mentor your team with best practices for your Cassandra infrastructure and performance.
- Optimize existing Cassandra Clusters.
- Troubleshoot and Fine-tune Cassandra performance issues.
- Provide hardware recommendations.
- Provide custom Cassandra training from beginner to advanced level.
- And offer any other related services including (Big Data, Search, NoSQL and RDBMS)
We have the expertise to understand your requirements and tackle your data problems. Our clients trust us to provide them with the knowledge and skill to tackle every challenge and succeed at every opportunity. Need expert help with Cassandra? Contact us today to unlock scalable, high-performance data solutions.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.