Cazton stands as a premier provider of top-notch Blockchain consulting and training services, spearheaded by a team of seasoned Blockchain Specialists, Consultants, and Developers. Our comprehensive approach begins with a meticulous assessment of your business requirements, allowing us to determine whether Blockchain serves as the optimal solution for your unique needs. From conceptualization to implementation, our experts guide you through the entire Blockchain journey.
Our Blockchain consulting services extend beyond mere assessment, encompassing the development of tailored Blockchain solutions that seamlessly integrate with your existing network. This includes adeptly navigating tasks such as smart contract development and deployment, token creation, ICO auditing, and thorough smart contract audits to ensure the robustness and security of your Blockchain applications. Our expertise covers both public and private Blockchain creation, providing flexibility to adapt to diverse use cases.
Whether you are exploring Blockchain for the first time or seeking to enhance your existing capabilities, Cazton's Blockchain services offer a comprehensive and tailored approach to address your specific needs. Contact us now to embark on a transformative Blockchain journey with Cazton's expert guidance and innovative solutions.
iOS AI Consulting for Enterprises
Customizing Voice, Text, Picture & Video AISemantic Kernel
Scalable, production-ready AI solutions for enterprisesBlockchain
Pioneering innovations for various sectorsBig Data
Navigating and leveraging immense data landscapesApache Spark
Empowering data-driven decisions with proficiencyHadoop
Maximizing potential with its expansive capabilitiesKafka
Streamlining data processing with expertiseSpark.NET
Uniting Spark's power with the versatility of .NETOpenAI
Spearheading AI innovations with OpenAI expertiseAzure OpenAI
Everything you need to know about Azure OpenAIChatGPT for Business
Leveraging ChatGPT for enhanced business interactionsAI Express PoC Service
Fast-Track Your AI Journey with Express PoC ServicesTech Debt Terminator
Eradicating Technical Debt for Efficient Software DevelopmentOpenAI vs CaztonAI
Unveiling the distinctions and strengths between OpenAI and CaztonAIOpenAI Case Studies
Showcasing real-world implementations and successes with OpenAI technologiesPyTorch
Leveraging PyTorch for cutting-edge machine learning solutionsTensorFlow
Harnesse AI prowess for innovative solutionsMicrosoft Fabric
Implementing scalable and reliable distributed applications with Microsoft FabricDatabricks
Unlocking the potential of Databricks for data analyticsAzure Cosmos DB
All you need to knowTop Services




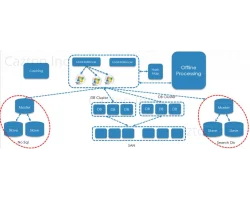




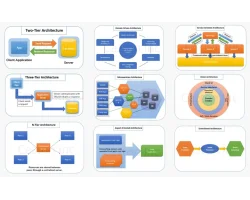

Work with senior consultants and keep the team right-sized
You can engage a senior leader for a focused window, bring them back on a cadence, or run a longer delivery program with a blended team.