Spark Consulting
- Accelerate business insight at scale: Apache Spark lets enterprises process massive datasets at remarkable speed, enabling faster, deeper insights and transforming how data informs strategic decisions.
- Scale your AI and ML with confidence: Our experts design end-to-end ML systems using Spark that accelerates development, simplifies operations and ensures compatibility with enterprise scale AI platforms.
- Unified analytics across cloud and on-prem: Our solutions unify real-time and batch workloads across hybrid and multi-cloud environments including Azure, AWS, GCP and on-prem, so you can build analytics systems that scale with your business.
- Improved performance at every stage: We proactively detect and resolve performance issues before they escalate by applying proven tuning techniques to keep systems fast, reliable, and cost effective.
- Your trusted partner from start to scale: We go beyond implementation to guide you through planning, deployment, and optimization; ensuring your Spark investment delivers meaningful business outcomes.
- Microsoft and Cazton: We work closely with Data Platform, OpenAI, Azure OpenAI and many other Microsoft teams. Thanks to Microsoft for providing us with very early access to critical technologies.
- Trusted by leading enterprises: From Fortune 500s to fast-growing startups, we’ve helped organizations across industries succeed with Big Data, Cloud, and AI development, deployment, consulting, recruiting and hands-on training services. Our clients include Microsoft, Broadcom, Thomson Reuters, Bank of America, Macquarie, Dell, and more.
Your organization generates more data every day than many companies processed in entire years just a decade ago. Yet despite investing millions in data infrastructure, most executives find themselves asking the same frustrating question: why does it still take weeks to get meaningful insights from our data?
The answer lies not in collecting more data, but in fundamentally rethinking how you process it. Apache Spark represents a paradigm shift in enterprise data processing, enabling organizations to analyze massive datasets in real-time while reducing infrastructure costs and complexity. However, implementing Spark effectively requires more than just technical knowledge; it demands strategic alignment with business objectives, seamless integration with existing systems, and a clear roadmap for scaling capabilities. Many organizations struggle to bridge the gap between Spark's potential and actual business value.
This is where strategic implementation of partnership becomes essential. With deep expertise in both the technical intricacies of Spark and the business challenges of enterprise data transformation, we provide the guidance, implementation support, and optimization strategies needed to turn Spark's capabilities into tangible business outcomes.
Why Spark Matters to Your Business Strategy
The demand for big data analytics continues to grow rapidly as organizations look to turn massive data assets into competitive advantage. Apache Spark has emerged as the leading processing engine in this landscape, outpacing traditional frameworks with its speed, versatility, and developer-friendly APIs.
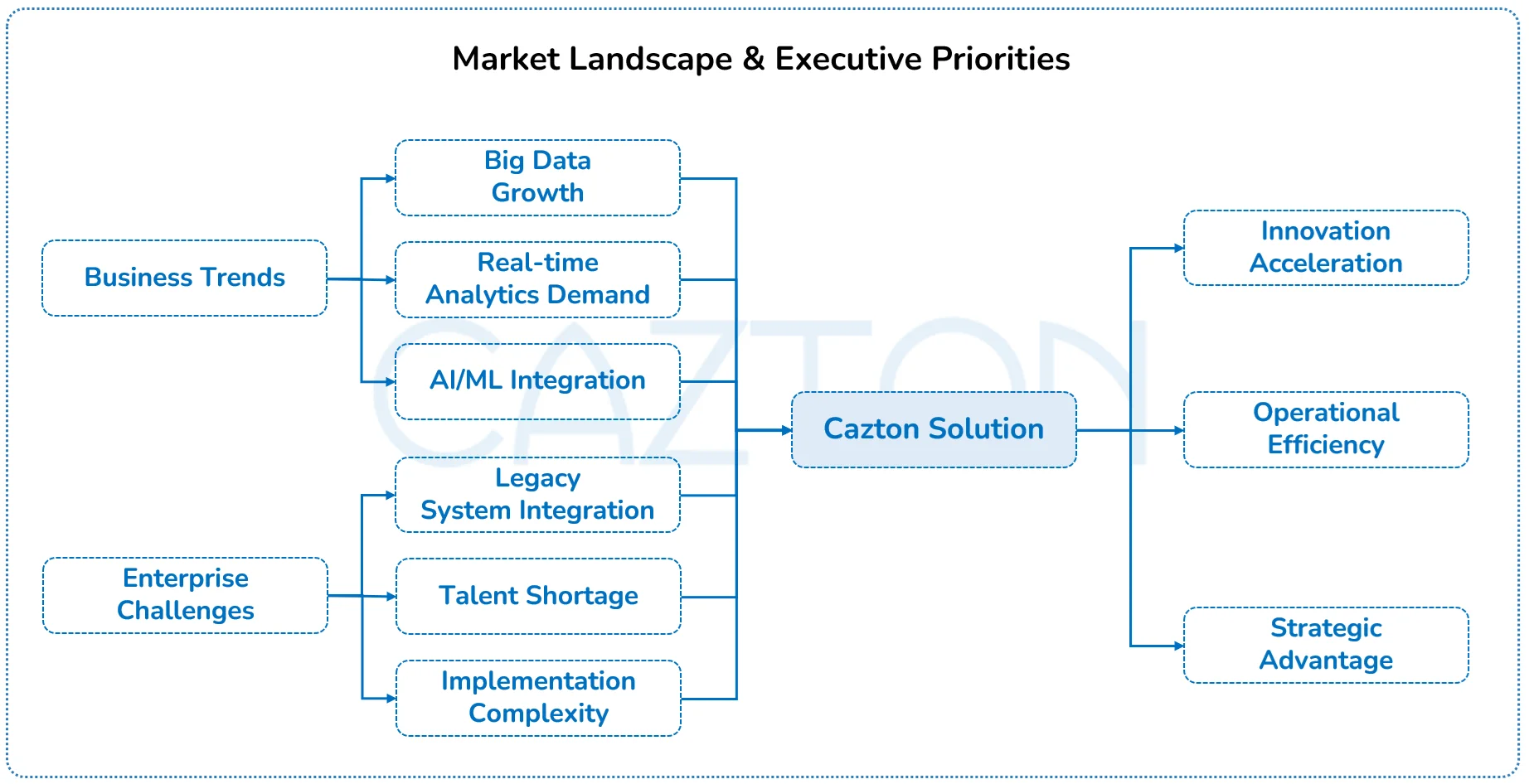
Despite its advantages, many enterprises hesitate to adopt Spark due to concerns about integration complexity, skill requirements, and unclear ROI. Others rush implementation without proper planning, resulting in underperforming systems that fail to deliver expected business value. The gap between Spark's technical capabilities and realized business outcomes remains substantial for many organizations.
What sets successful implementations apart is a strategic approach that aligns Spark's capabilities with specific business objectives, integrates seamlessly with existing data infrastructure, and builds internal capabilities for long-term success. Our consultants bring this strategic perspective, along with deep technical expertise, to ensure your Spark implementation delivers measurable business impact from day one.
What Executives Should Know About Spark
Apache Spark is a unified analytics engine designed for large-scale data processing. Unlike traditional batch processing frameworks, Spark processes data in-memory, enabling speeds up to 100 times faster for certain applications while maintaining the scalability, fault tolerance, and reliability required for enterprise workloads.
At its core, Spark consists of several integrated components:
- Spark Core is the foundation that provides distributed task execution.
- Spark SQL for structured data processing.
- Spark Streaming for real-time data analysis.
- MLlib for machine learning.
- GraphX for graph computation.
These components work together to provide a comprehensive platform for diverse data processing needs.
What makes Spark particularly valuable for enterprises is its ability to handle multiple workloads, batch processing, interactive queries, real-time analytics, and machine learning, within a single system. This versatility eliminates the need for multiple specialized systems, reducing complexity and cost while enabling more sophisticated data applications.
Our expertise helps organizations navigate Spark's capabilities, identifying the optimal components and configurations for specific business needs while ensuring proper integration with existing data infrastructure and business processes.
What AI and Spark Can Do for Your Business
Are you investing millions in AI initiatives but struggling to get meaningful results? Most organizations remain stuck in pilot phases without real business impact. The challenge isn't collecting more data or buying more tools, it's creating infrastructure that makes AI work at enterprise scale.
Apache Spark becomes your strategic advantage, transforming from a data processing tool into the foundation for intelligent business operations.
Accelerated AI Training and Development
How long does it take to train machine learning models on your customer data? Days? Weeks? Spark's integration with deep learning frameworks enables distributed training, reducing model training time to hours while processing 100 times more data.
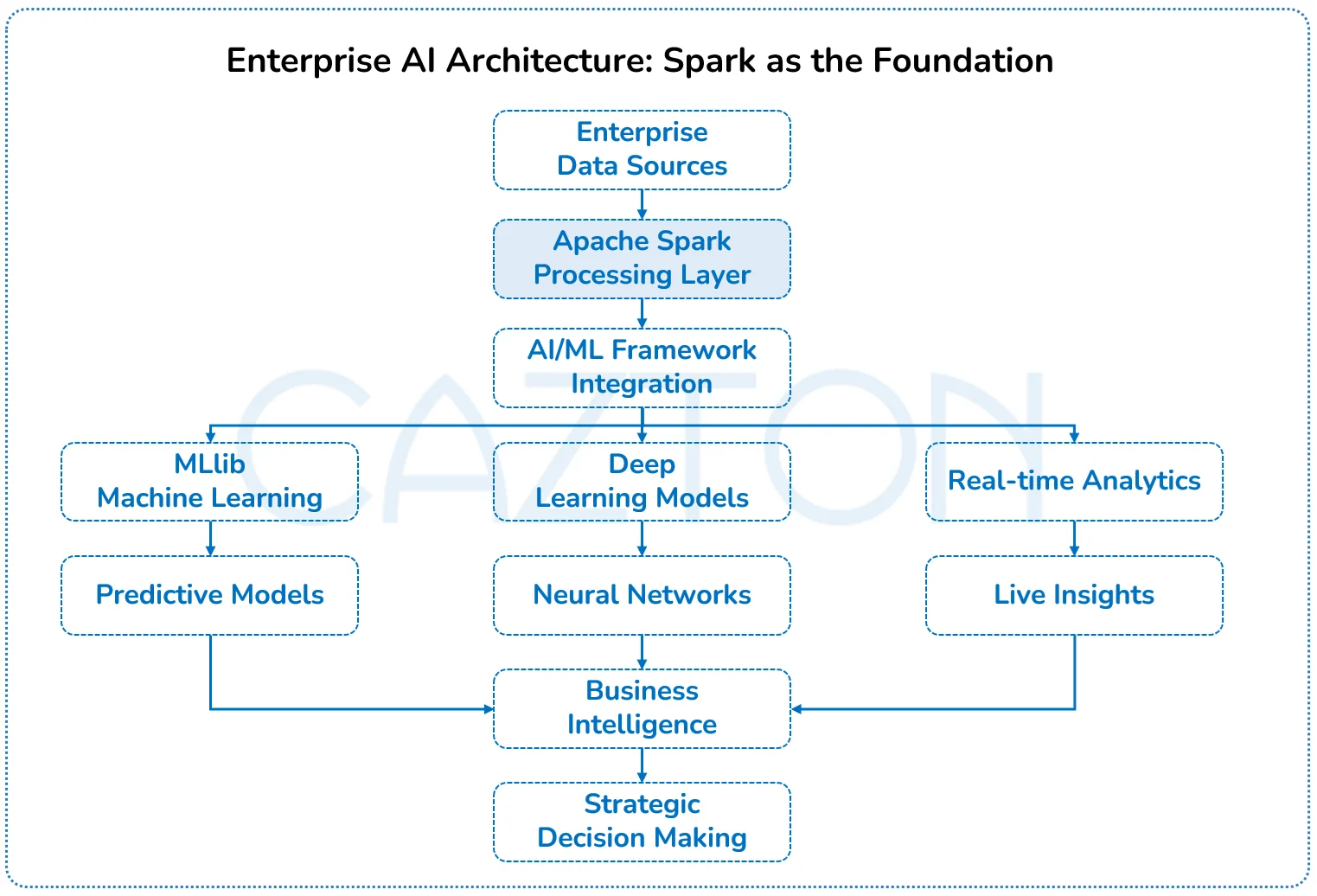
We handle complex data preparation and infrastructure setup, allowing AI models to train on complete datasets rather than small samples. This delivers more accurate and reliable results while reducing your internal resource burden.
Real-Time Intelligence That Drives Business Value
Transform your business operations with real-time AI analysis. Instead of waiting for daily reports, your AI models analyze customer behavior patterns instantly, automatically adjusting pricing strategies, inventory levels, or marketing campaigns based on live data streams.
Fraud detection systems process millions of transactions simultaneously, identifying suspicious patterns within seconds rather than discovering fraud in days. Supply chain optimization becomes proactive, with AI models continuously analyzing market conditions to prevent disruptions before they impact your business.
How We Bridge AI and Spark for Your Success
We help organizations implement AI-powered Spark solutions that deliver measurable business outcomes. Our expertise spans foundational infrastructure to advanced AI applications, including integration with leading platforms and frameworks.
We combine deep Spark expertise with real world AI experience to help you turn complex data into intelligent business outcomes.
- End to end implementation support from data engineering and infrastructure setup to full scale AI and ML pipeline deployment using Spark.
- Integration with leading AI frameworks including MLlib, TensorFlow, PyTorch and cloud native tools across Azure, AWS, and GCP.
- Scalable architecture design that enables real time model training inference and decision making across massive datasets.
- Proven delivery methodologies that turn pilot projects into production ready AI systems with measurable business impact.
Whether you're exploring generative AI, implementing machine learning pipelines, or building intelligent automation, we provide strategic guidance and technical implementation that transforms AI experiments into competitive advantages. Our proven methodologies ensure your AI initiatives scale effectively while delivering real-time insights your business needs.
Preparing Your Organization for Success
While Apache Spark offers tremendous potential, off-the-shelf implementations often fall short in enterprise environments. Complex data architectures, stringent security requirements, and performance expectations demand customized approaches that generic solutions cannot provide.
Security and compliance represent significant challenges, particularly in regulated industries. Spark's distributed nature requires careful planning around data governance, access controls, and audit capabilities to meet enterprise standards. Similarly, scaling Spark effectively across large datasets and user bases requires expertise in resource management, workload optimization, and infrastructure design.
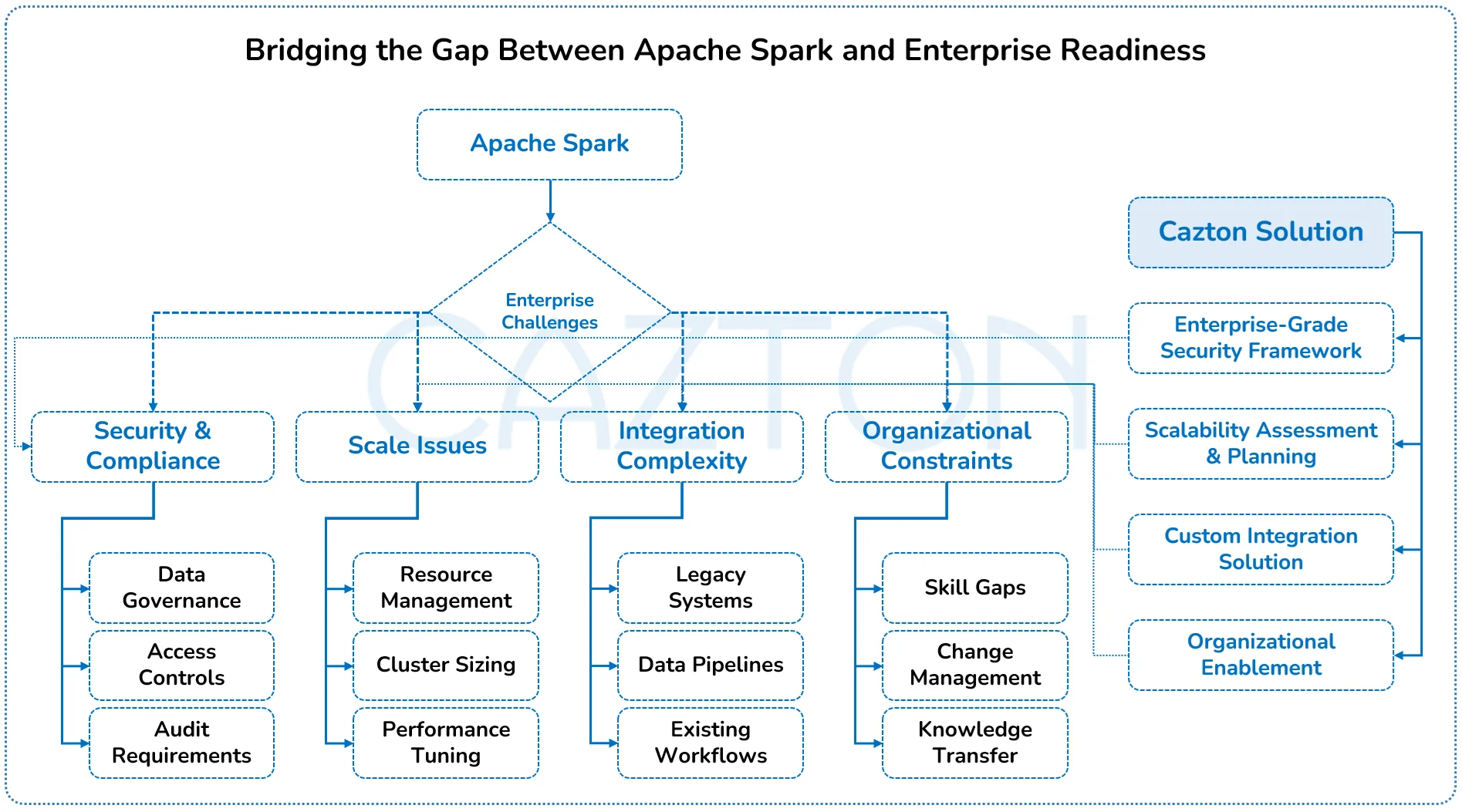
Organizational factors also impact success. Without proper skills transfer and change management, even technically sound implementations can fail to deliver value. The gap between data engineering teams and business users must be bridged through appropriate interfaces, workflows, and training.
Expert guidance is essential to navigate these challenges. Our consultants bring proven methodologies for assessing enterprise readiness, identifying potential risks, and developing mitigation strategies that ensure successful adoption and value realization.
Case Studies
AI Model Lifecycle Automation
- Problem: A technology firm developing advanced AI solutions faced delays in training and deploying machine learning models due to disconnected workflows and infrastructure limitations. The data science team worked with fragmented datasets and manual processes, which slowed experimentation, increased error rates, and made model reproducibility challenging. As datasets grew, the lack of scalable infrastructure became a bottleneck to progress, limiting how quickly insights could reach production systems.
- Solution: We built a Spark-based AI lifecycle platform that unified data preprocessing, feature engineering, model training, and deployment into a single scalable pipeline. The platform integrated with MLflow for experiment tracking and supported both PyTorch and TensorFlow models. Spark’s distributed processing enabled efficient training on full datasets, while seamless orchestration reduced model delivery timelines. Reusable components were built to automate retraining workflows and ensure consistency across environments.
- Business impact: Data scientists accelerated experimentation and improved collaboration with standardized, scalable workflows. Models were trained on complete datasets, improving accuracy and reliability in production. The organization was able to shorten the time from prototype to deployment, improving the overall return on AI investments.
- Tech stack: Apache Spark, MLflow, TensorFlow, PyTorch, Delta Lake, Azure Machine Learning, Azure Kubernetes Service, Docker, PostgreSQL, Airflow, React.js, .NET.
Real-Time Marketing Analytics
- Problem: A national retail chain faced challenges in delivering timely marketing insights due to slow and fragmented analytics workflows. Data from point-of-sale systems, mobile apps, and customer loyalty programs was processed in separate pipelines, creating latency in understanding customer trends. Marketing teams had to rely on outdated reports, which made campaign decisions reactive rather than proactive.
- Solution: We implemented a unified Spark-based analytics platform that ingested data from in-store transactions, mobile activity, and loyalty databases in near real-time. The platform supported customer segmentation, dynamic pricing models, and campaign performance tracking all available through self-service dashboards. Integration with existing data warehouses and marketing systems ensured continuity while enabling real-time decision-making.
- Business impact: The marketing team gained rapid insight into customer behavior, allowing for real-time campaign adjustments and more targeted promotions. Inventory planning became more responsive, and customer engagement improved due to faster feedback loops. Data silos were eliminated, making insights broadly accessible across departments.
- Tech stack: Apache Spark, Kafka, AWS Kinesis, AWS S3, SQL Server, Delta Lake, Tableau, Databricks, Java, Angular, Progressive web apps, Ionic.
Energy Grid Monitoring and Predictive Maintenance
- Problem: A utility provider managing a large energy grid was struggling to detect anomalies and predict equipment failures in time to prevent outages. Their existing systems relied heavily on post-facto reporting and manual diagnostics, creating operational risks. IoT sensor data from substations, transformers, and field equipment was generated at high velocity, but their legacy systems couldn't process it fast enough for proactive responses.
- Solution: We deployed a Spark-based monitoring and analytics platform that ingested high-frequency sensor data in real time. Machine learning models were trained on historical failure patterns to provide predictive alerts, while rule-based anomaly detection flagged early signs of equipment degradation. Spark Streaming enabled rapid event processing, while dashboards gave operations teams a clear view of grid health across regions.
- Business impact: The organization shifted from reactive to proactive maintenance, significantly reducing equipment downtime. Operational efficiency improved as field teams were dispatched based on predictive insights rather than manual checks. Real-time monitoring enabled faster response to grid issues, increasing service reliability and safety.
- Tech stack: Apache Spark, Kafka, Databricks, Node.js, MongoDB, Grafana, GCP Pub/Sub, Vertex AI, OpenAI, TensorFlow, PyTorch, MLflow, Power BI.
Content Personalization in Digital Media
- Problem: A digital media platform struggled to deliver timely personalized content recommendations due to slow batch pipelines and inconsistent user data processing. Behavioral data from multiple platforms: web, mobile, and connected devices was siloed, and recommendation algorithms were trained on outdated snapshots, resulting in poor user engagement.
- Solution: We created a Spark-based personalization engine that consolidated real-time user interaction data across devices and generated dynamic content recommendations. Spark streaming was used to process clickstream data, while MLlib models trained on audience behavior predicted user interests in near real time. The platform included modular APIs to deliver recommendations to different front-end systems with minimal latency.
- Business impact: The platform significantly improved content relevance and user retention by delivering personalized experiences that were adapted in real time. Data freshness and model accuracy increased, leading to stronger engagement metrics across channels. Teams gained a unified view of audience behavior, informing both editorial and monetization strategies.
- Tech stack: Apache Spark, MLlib, .NET, Kafka, React.js, React Native, Azure Cosmos DB, Redis, Azure Event Hubs, Azure Data Lake, Python.
Retail Inventory Modernization with Databricks
- Problem: A global retail enterprise faced significant delays in inventory analytics, with updates taking up to 24 hours across more than 5,000 stores. Their self-managed Apache Spark cluster required constant operational oversight, limiting the team’s ability to scale during peak demand events like Black Friday. The infrastructure bottleneck also prevented timely deployment of machine learning models, delaying key insights for inventory planning and customer experience optimization.
- Solution: We migrated their analytics workloads to Databricks, enabling managed scalability and reduced operational overhead. Delta Lake was implemented for near real-time inventory tracking, and AutoML was used to support demand forecasting initiatives. The new architecture allowed the data team to shift from infrastructure management to innovation, accelerating delivery of new analytics products.
- Business impact: Inventory analytics now update more frequently, leading to a noticeable reduction in stockout incidents and a significant drop in infrastructure costs. Most importantly, the data team shifted focus from managing infrastructure to delivering new analytics capabilities, successfully launching several new machine learning models shortly after the migration.
- Tech stack: Databricks, Delta Lake, AutoML, Apache Spark, MLflow, Python, Azure SQL, Azure Data Lake Storage, Power BI.
Advanced Apache Spark Implementations
Enterprises seeking maximum value from Apache Spark must go beyond basic implementations to address specific business requirements and technical constraints. Major implementation challenges include data pipeline complexity, performance optimization across diverse workloads, and integration with specialized industry systems.
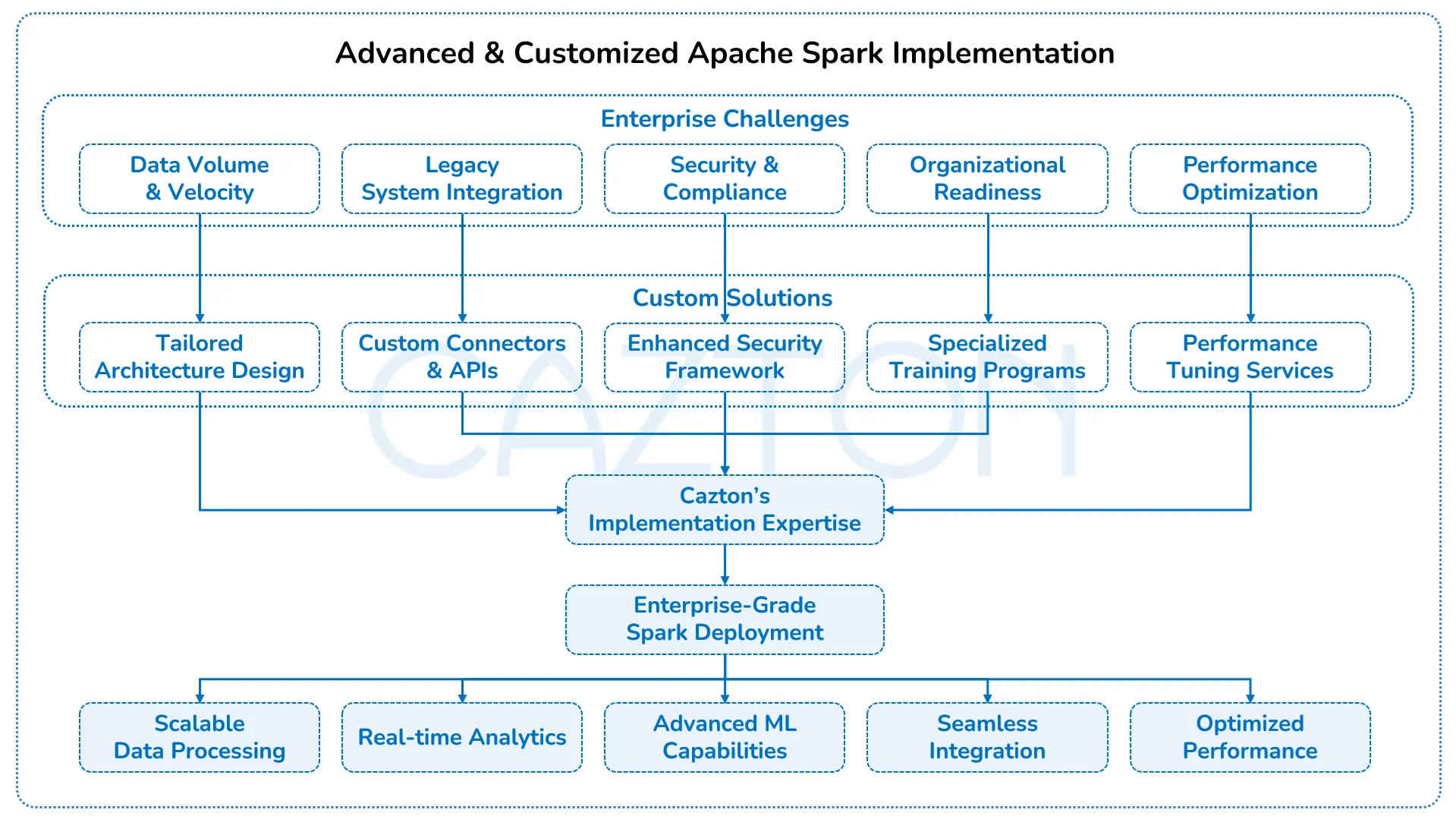
Mature organizations leverage Spark's extensibility to create custom components tailored to their unique needs. This includes specialized data connectors for proprietary systems, custom optimizers for industry-specific workloads, and extended monitoring capabilities for enterprise operations teams. These customizations transform Spark from a general-purpose tool to a strategic business asset.
Our implementations are built to solve complex enterprise challenges with precision, performance, and scalability.
- We design advanced Spark architectures that address real world enterprise constraints, including legacy system integration, regulatory compliance, and high-volume workloads.
- Our team develops custom components such as proprietary connectors, industry specific optimizers, and security frameworks to extend Spark beyond out of the box capabilities.
- We deliver implementation patterns and tuning strategies proven across industries to ensure scalable high performing and maintainable Spark deployments at enterprise scale.
Our consultants bring field-tested solutions for common enterprise challenges, such as multi-tenant Spark clusters that maintain security boundaries while optimizing resource utilization, hybrid batch/streaming architectures that balance throughput and latency requirements, and specialized machine learning pipelines that accelerate model development and deployment.
Through our engagements with organizations across industries, we've developed reusable patterns and components that accelerate implementation while maintaining the customization necessary for enterprise success. Our expertise spans the full spectrum from architecture design through performance tuning to operational excellence.
Accelerating Your Spark Journey to Production
While Apache Spark provides powerful data processing capabilities, many enterprises struggle with the complexity of managing Spark clusters, optimizing performance, and enabling collaboration across teams. Databricks addresses these challenges by providing a unified analytics platform that simplifies Spark deployment while adding enterprise-grade features that accelerate time-to-value.
The gap between implementing raw Spark and achieving production-ready analytics at scale has led many organizations to seek managed solutions. Databricks transforms Spark from a powerful but complex framework into an accessible, enterprise-ready platform that data teams can leverage immediately. However, maximizing Databricks' potential still requires strategic implementation aligned with your specific business objectives.
Why Databricks Changes the Enterprise Spark Equation
Databricks eliminates the infrastructure complexity that often derails Spark initiatives. Instead of managing clusters, configuring networks, and optimizing resource allocation, your teams focus on delivering business value through analytics and machine learning. The platform's automated cluster management reduces operational overhead by up to 80% while improving performance through built-in optimizations.
Enterprise features transform how organizations govern and secure their data assets. Unity Catalog provides centralized governance across all data and AI assets, while fine-grained access controls ensure compliance with regulatory requirements. Collaborative notebooks enable data scientists, engineers, and analysts to work together seamlessly, breaking down silos that traditionally slow analytics projects.
Databricks vs. Traditional Spark and the Business Impact
Traditional Spark deployments require significant expertise in distributed systems, cluster management, and performance optimization. Organizations often spend months setting up infrastructure before processing their first dataset. Databricks reduces this timeline to days while providing superior performance through innovations like the Photon engine, which accelerates queries by up to 12x compared to standard Spark.
Cost optimization becomes automatic with Databricks' intelligent resource management. The platform automatically scales clusters based on workload demands, shutting down idle resources, and preventing cost overruns. Organizations often experience substantial cost savings compared to managing Spark clusters on their own while achieving better performance and reliability.
Key Databricks Capabilities That Drive Business Value'
Delta Lake fundamentally changes data lake reliability by bringing ACID transactions to cloud storage. This means your data teams can update massive datasets without worrying about corruption or inconsistency, enabling real-time analytics on constantly changing data. Financial services firms use Delta Lake to maintain accurate, up-to-the-minute risk calculations across billions of transactions.
MLflow integration streamlines the entire machine learning lifecycle from experimentation to production deployment. Data scientists track experiments, compare models, and deploy winning solutions without switching platforms. This integrated approach reduces model deployment time from months to weeks while improving reproducibility and governance.
The Photon engine represents a quantum leap in processing performance, particularly for SQL workloads and data transformations. By leveraging vectorized execution and advanced query optimization, Photon enables interactive analytics on datasets that previously required overnight batch processing.
Enterprise Integration Excellence
Databricks excels at connecting with existing enterprise data infrastructure. Native connectors for major data warehouses, cloud storage services, and business applications ensure seamless data flow. Whether pulling data from SAP, pushing results to Tableau, or synchronizing with Snowflake, Databricks maintains high-performance connectivity without custom development.
Our implementations leverage Databricks' REST APIs and partner integrations to create end-to-end analytics pipelines. Real-time data from Kafka streams combined with historical data in Delta Lake, feeding machine learning models that update business dashboards automatically. This orchestration happens reliably at scale, processing millions of events per second when needed.
How We Accelerate Databricks Success
Our Databricks expertise spans the complete implementation lifecycle, from initial assessment through ongoing optimization. We help organizations migrate existing Spark workloads to Databricks while redesigning architectures to leverage platform-specific capabilities like Delta Lake and Unity Catalog.
Migration strategies preserve existing investments while unlocking new capabilities. We assess current Spark implementations, identify optimization opportunities, and execute phased migrations that minimize disruption. Organizations maintain business continuity while gaining immediate benefits from Databricks' managed infrastructure and enhanced performance.
Architecture design for Databricks environments requires understanding both the platform's capabilities and your specific business requirements. We design workspace organization strategies, implement cost optimization frameworks, and establish development lifecycle processes that scale across teams and projects.
Our assessment approach evaluates your current Spark usage, data architecture, and team capabilities to identify the optimal Databricks implementation strategy. We recommend starting with pilot projects that demonstrate clear business value while building internal expertise and confidence with the platform.
Pilot project selection focuses on use cases that showcase Databricks' advantages: real-time analytics, collaborative machine learning, or complex data transformations that benefit from managed infrastructure. These initial successes create momentum for broader adoption while providing valuable learning opportunities.
Design Enterprise-Grade Infrastructure
Successful Spark implementations require careful attention to backend infrastructure design that supports both current requirements and future scaling needs. The architectural foundation determines long-term success and operational efficiency.
- Data flow design represents a critical component of Spark architecture. Effective implementations create clear data pipelines that handle ingestion, processing, and output while maintaining data quality and lineage. This includes designing appropriate data partitioning strategies, implementing efficient caching mechanisms, and creating robust error handling procedures.
- User experience requirements for enterprise-grade Spark deployments extend beyond technical functionality. Business users need intuitive interfaces for accessing processed data, while data engineers require sophisticated tools for managing and monitoring Spark jobs. Creating interfaces that serve both audiences requires careful design and implementation.
- Integration with legacy systems presents unique architectural challenges. Most enterprises have significant investments in existing data warehouses, business intelligence tools, and operational systems. Successful Spark implementations create seamless connectivity while maintaining the performance and reliability of existing infrastructure.
- Modern technology stack integration enables Spark to work effectively with cloud-native services, container orchestration platforms, and microservices architectures. This includes implementing appropriate security controls, monitoring capabilities, and deployment automation that align with enterprise standards.
- Key architectural decisions include cluster sizing and configuration, storage format optimization, and network topology design. These choices significantly impact performance, cost, and operational complexity. We bring extensive experience in making these decisions based on your specific requirements and constraints.
- Dependency management becomes increasingly complex in enterprise environments where Spark must integrate with numerous external systems and services. Proper architectural design minimizes dependencies while ensuring reliable operation and simplified maintenance procedures.
Our architectural approach focuses on creating resilient, scalable solutions that deliver consistent performance while minimizing operational overhead. We work closely with your technical teams to ensure that architectural decisions align with your overall enterprise strategy and technical standards.
Move Beyond Pilots and Scale
Implementing Apache Spark effectively requires a phased approach aligned with business priorities. We recommend starting with high-value use cases that demonstrate quick wins while building the foundation for broader adoption. This approach builds organizational momentum and provides valuable learning opportunities.
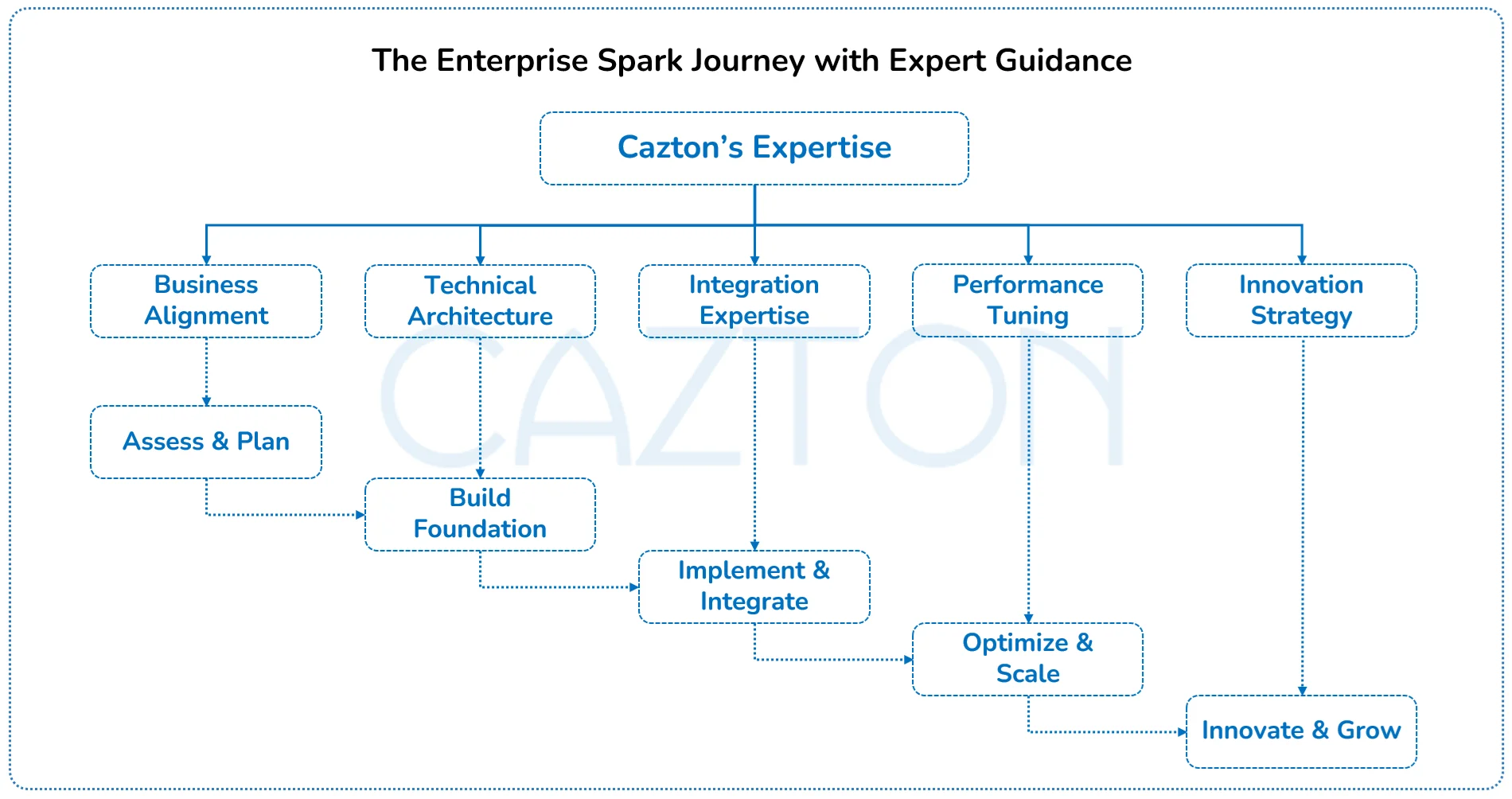
The initial phase focuses on establishing foundational infrastructure and proving value through targeted use cases. This includes setting up development environments, training key personnel, and implementing pilot projects that demonstrate clear business benefits. Starting with well-defined, manageable projects builds confidence and momentum for broader adoption.
- Governance frameworks become essential as Spark usage expands across the organization. This includes establishing data quality standards, implementing security protocols, and creating operational procedures that ensure consistent performance and compliance. Proper governance prevents common pitfalls that can derail larger implementations.
- Capability building involves both technical training and organizational change management. Technical teams need deep expertise in Spark development and operations, while business users require training in new analytical capabilities and workflows. Building internal expertise reduces dependency on external resources while improving long-term sustainability.
- Organizational enablement extends beyond training to include establishing centers of excellence, creating best practice documentation, and implementing knowledge sharing processes. These initiatives ensure that Spark expertise grows throughout the organization and that lessons learned benefit future projects.
- Performance measurement requires establishing appropriate metrics and KPIs that track both technical performance and business outcomes. This includes monitoring processing speeds, resource utilization, and system reliability while also measuring business impact through improved decision-making and operational efficiency.
- Future-proofing strategies ensure that your Spark investment continues to deliver value as technology evolves and business requirements change. This includes designing flexible architectures that can adapt to new requirements, implementing automated scaling capabilities, and maintaining compatibility with emerging technologies.
- Scalability planning addresses both technical and organizational scaling requirements. As data volumes grow and more teams adopt Spark, infrastructure must scale efficiently while maintaining performance standards. This includes planning for additional compute resources, storage capacity, and network bandwidth.
We guide organizations through each phase of implementation, providing expertise and support that ensures successful adoption and long-term value realization. Our proven methodologies help organizations avoid common pitfalls while accelerating time-to-value for their Spark investments.
How Cazton Can Help With Apache Spark
Organizations worldwide trust us to transform their data processing capabilities through strategic Spark implementations that deliver measurable business value. Our comprehensive approach ensures that your Spark investment not only meets current requirements but also scales to support future growth and evolving business needs.
We begin every engagement with a thorough assessment of your current data landscape, business objectives, and technical constraints. This analysis forms the foundation for a customized implementation strategy that addresses your specific challenges while maximizing the business value of your Spark deployment. Our experienced team works closely with your stakeholders to ensure that technical decisions align with strategic business goals.
Our Spark consulting services include:
- Custom architecture design and implementation tailored to your specific business requirements and technical constraints.
- Databricks migration and optimization services that transition existing Spark workloads to managed environments while maximizing platform-specific capabilities.
- Enterprise Databricks implementations including Unity Catalog setup, Delta Lake architecture, and MLflow integration for complete analytics lifecycle management.
- Enterprise integration services that seamlessly connect Spark with your existing data infrastructure and business systems.
- Performance optimization and tuning to maximize processing speed while minimizing infrastructure costs across both self-managed and Databricks environments.
- Security and compliance framework implementation ensuring your Spark environment meets industry standards and regulatory requirements, including Databricks-specific governance controls.
- Real-time analytics and streaming data processing solutions that enable immediate business insights and decision-making capabilities using Spark Streaming and Databricks' structured streaming.
- Advanced machine learning pipeline development leveraging both Spark MLlib and Databricks' AutoML capabilities for predictive analytics and business intelligence.
- Legacy system modernization that bridges traditional data processing with modern Spark capabilities, including migration paths to Databricks.
- Multi-cloud Databricks deployment and migration services across Azure Databricks, AWS Databricks, and hybrid environments.
- Databricks workspace optimization including cost management strategies, cluster configuration, and collaborative workflow design.
- Training and knowledge transfer programs covering both open-source Spark and Databricks platform capabilities to build comprehensive internal expertise.
- Ongoing optimization and support services that maintain peak performance and adapt to changing business requirements across your entire Spark ecosystem.
The data processing landscape has fundamentally changed, and organizations that fail to adapt risk falling behind competitors who can analyze information and respond to market changes in real-time. Apache Spark represents more than just a technology upgrade; it's a strategic transformation that can redefine how your organization creates value from data.
However, the gap between Spark's potential and enterprise reality remains significant. Successful implementation requires more than technical deployment; it demands strategic planning, custom architecture design, and ongoing optimization aligned with your business objectives. Organizations that attempt to implement Spark without proper expertise often find themselves with underperforming systems that fail to deliver expected business value.
The consulting-led approach ensures that your Spark implementation becomes a strategic asset rather than just another technology deployment. We bring proven methodologies, field-tested solutions, and deep expertise that accelerate time-to-value while avoiding common pitfalls that can derail enterprise implementations.
Your next step is to engage with our team for a comprehensive assessment of your current data processing challenges and strategic opportunities. We'll work with you to develop a customized roadmap that transforms your data capabilities while delivering measurable business outcomes. Contact us today to begin your organization's journey toward data-driven competitive advantage.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.